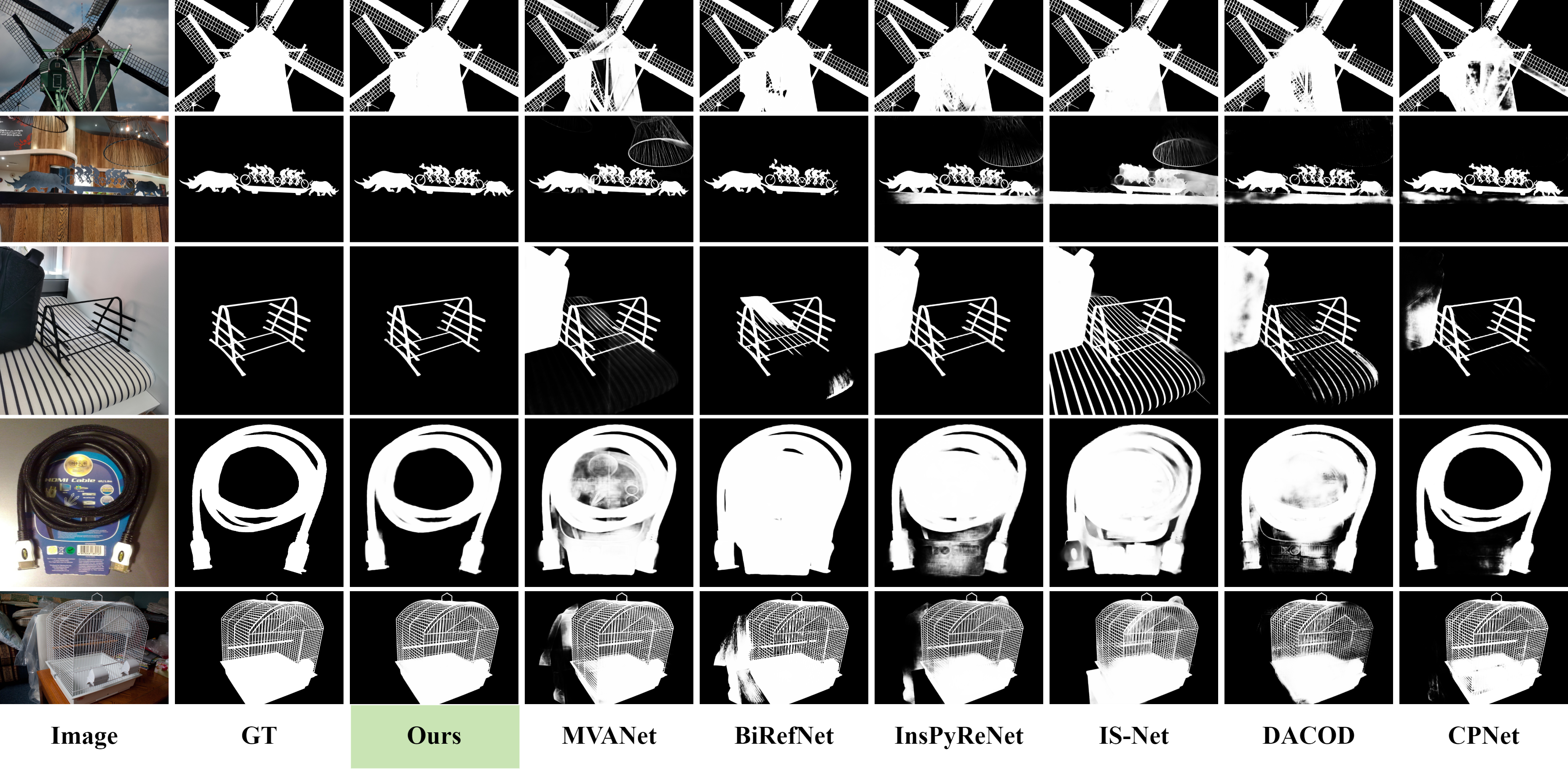
High-precision dichotomous image segmentation (DIS) is a task of extracting fine-grained objects from high-resolution images. Existing methods face a dilemma: non-diffusion methods work efficiently but suffer from false or missed detections due to weak semantics and less robust spatial priors; diffusion methods, using strong generative priors, have high accuracy but encounter high computational burdens.
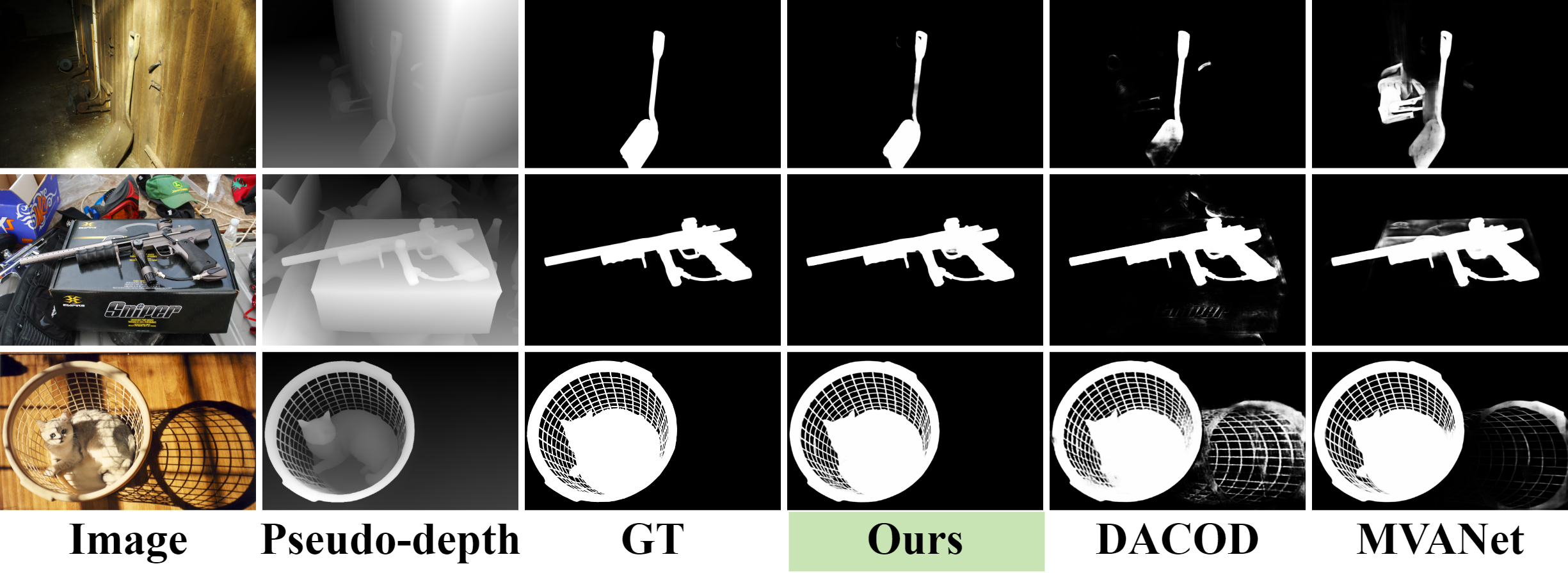
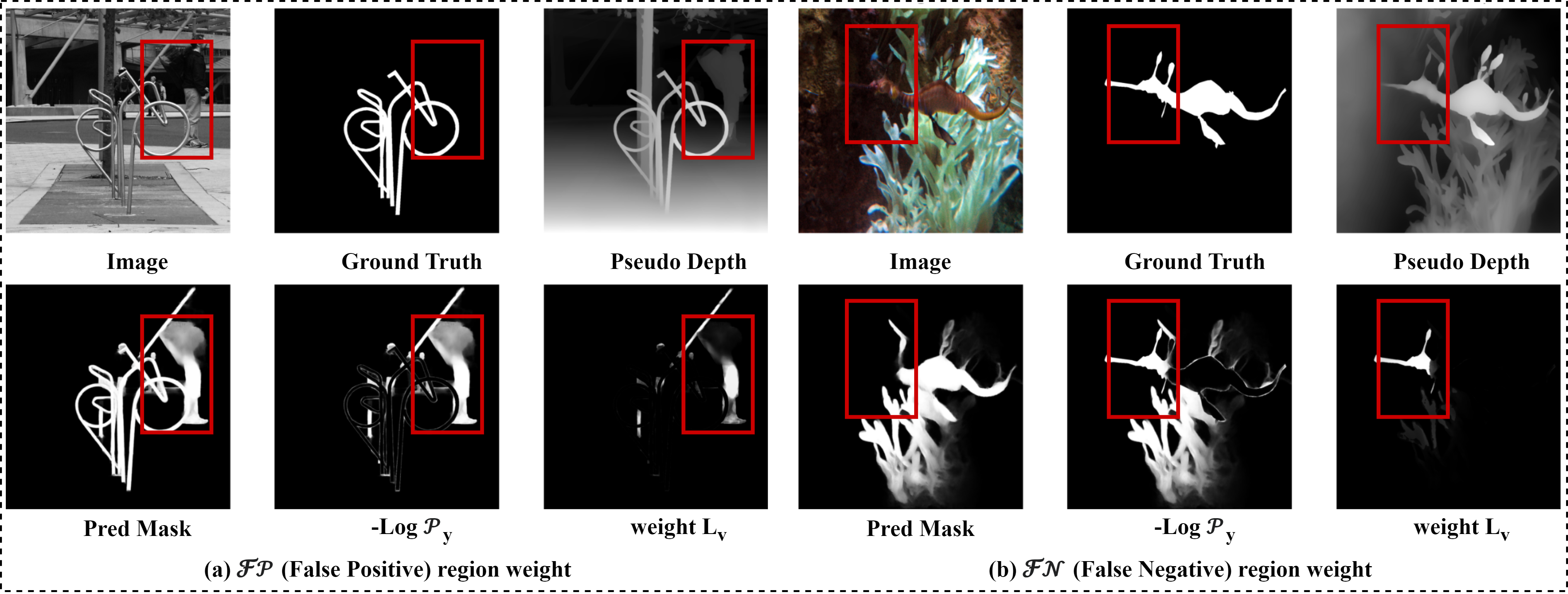
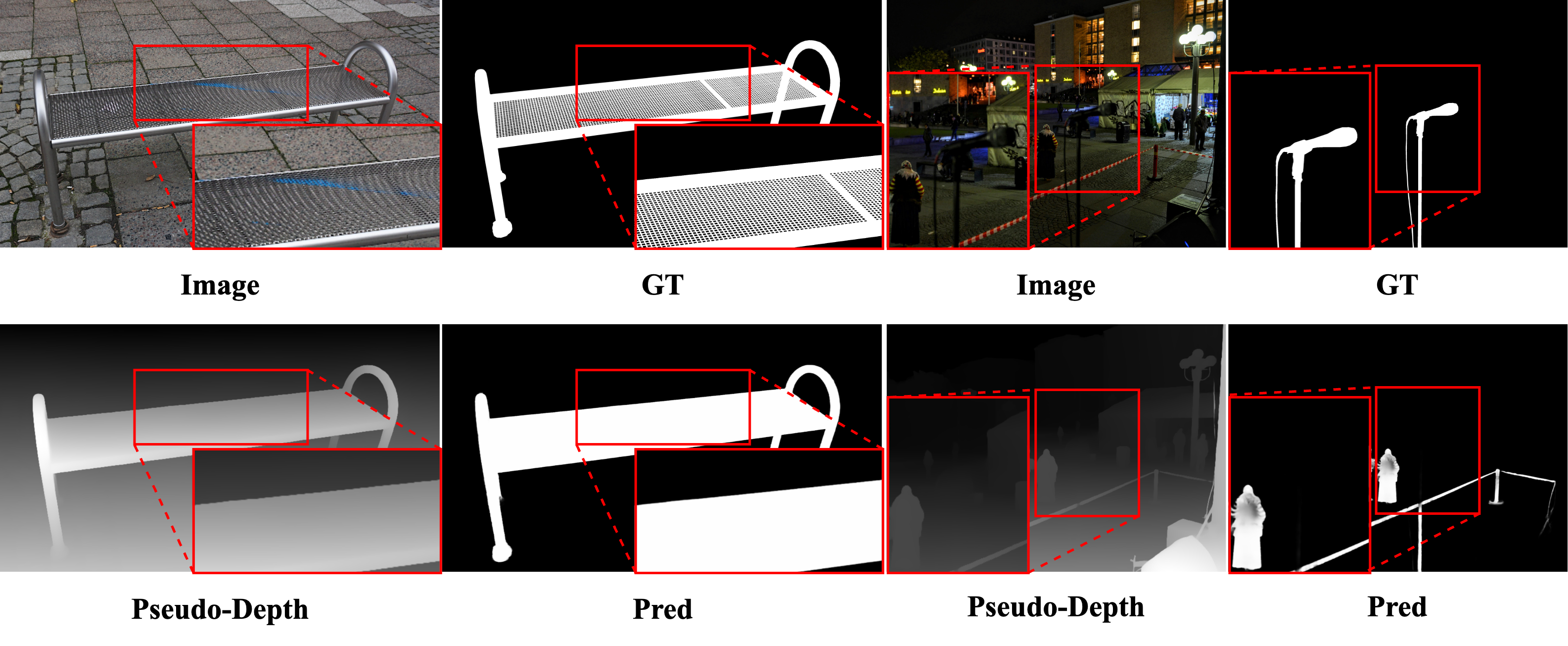
As a solution, we find pseudo depth information from monocular depth estimation models can provide essential semantic understanding that quickly reveals spatial differences across target objects and backgrounds. Inspired by this phenomenon, we discover a novel insight we term the depth integrity-prior: in pseudo depth maps, foreground objects consistently convey stable depth values with much lower variances than chaotic background patterns.
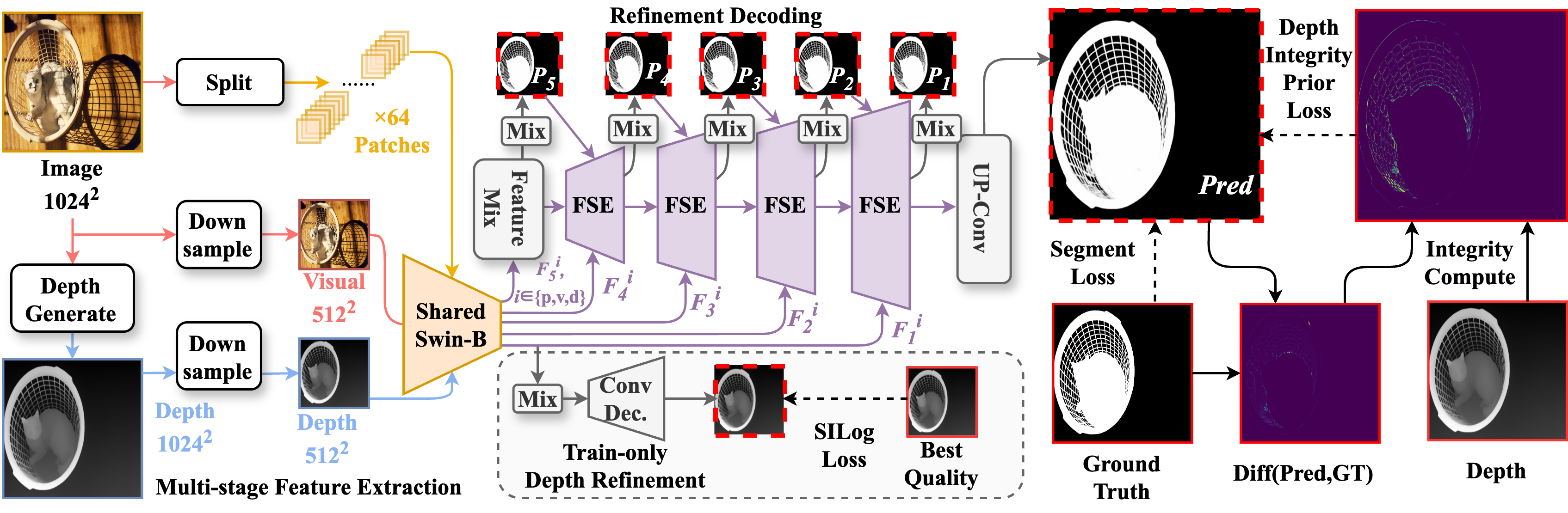
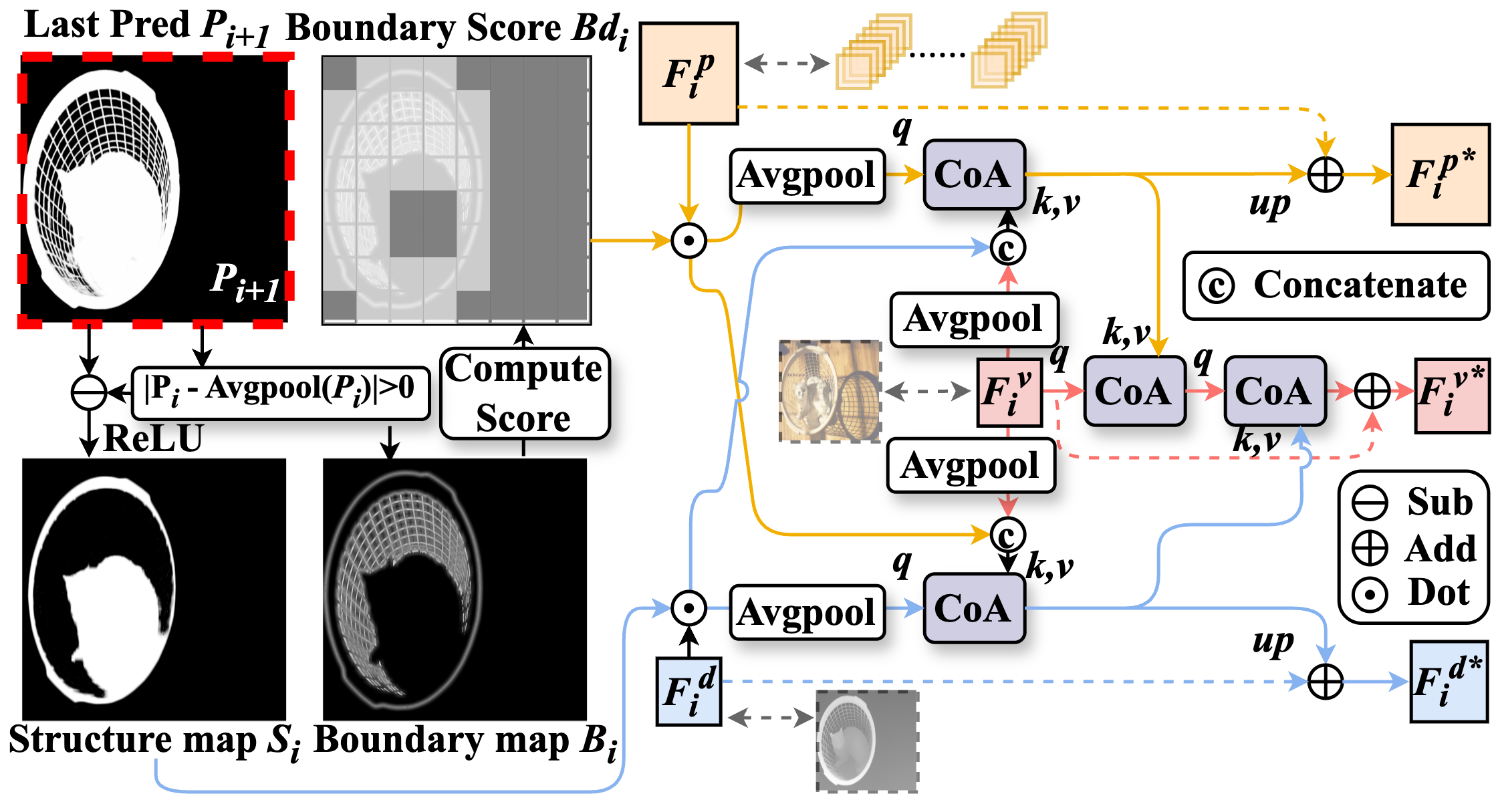
To exploit such a prior, we propose a Prior of Depth Fusion Network (PDFNet). Specifically, our network establishes multimodal interactive modeling to achieve depth-guided structural perception by deeply fusing RGB and pseudo depth features. We further introduce a novel depth integrity-prior loss to explicitly enforce depth consistency in segmentation results. Additionally, we design a fine-grained perception enhancement module with adaptive patch selection to perform boundary-sensitive detail refinement.