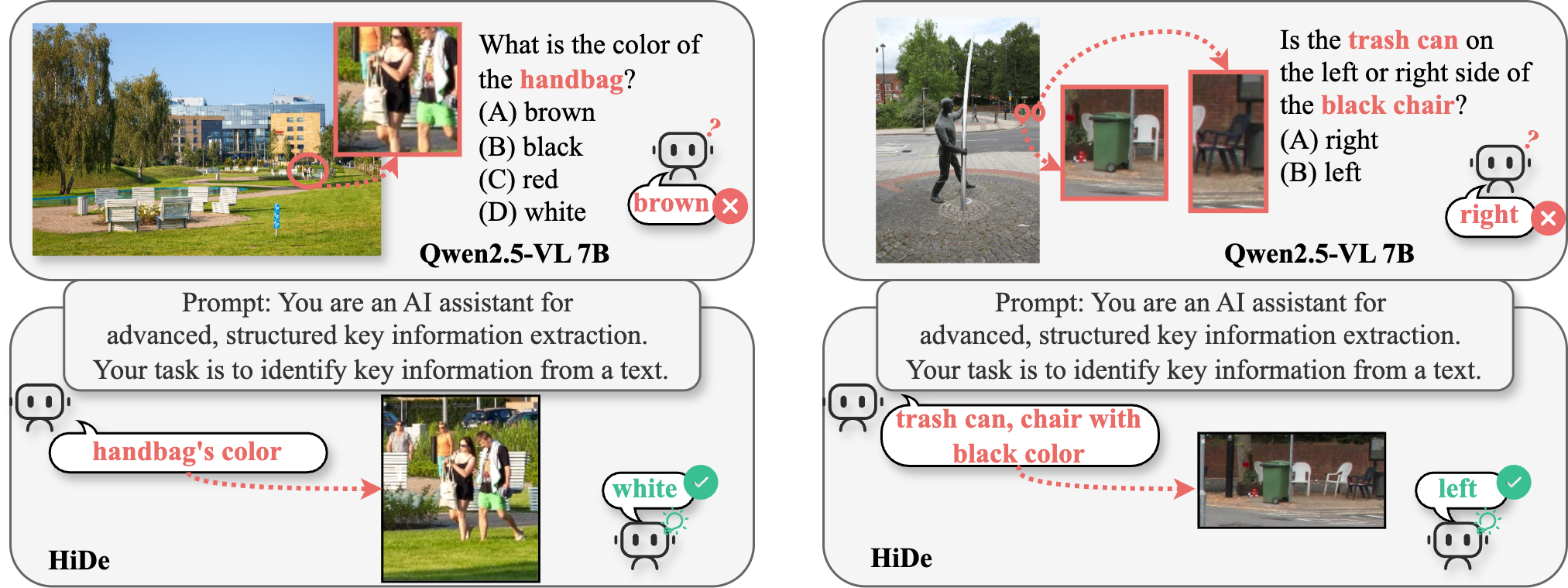
03 Hierarchical Decoupling Analysis
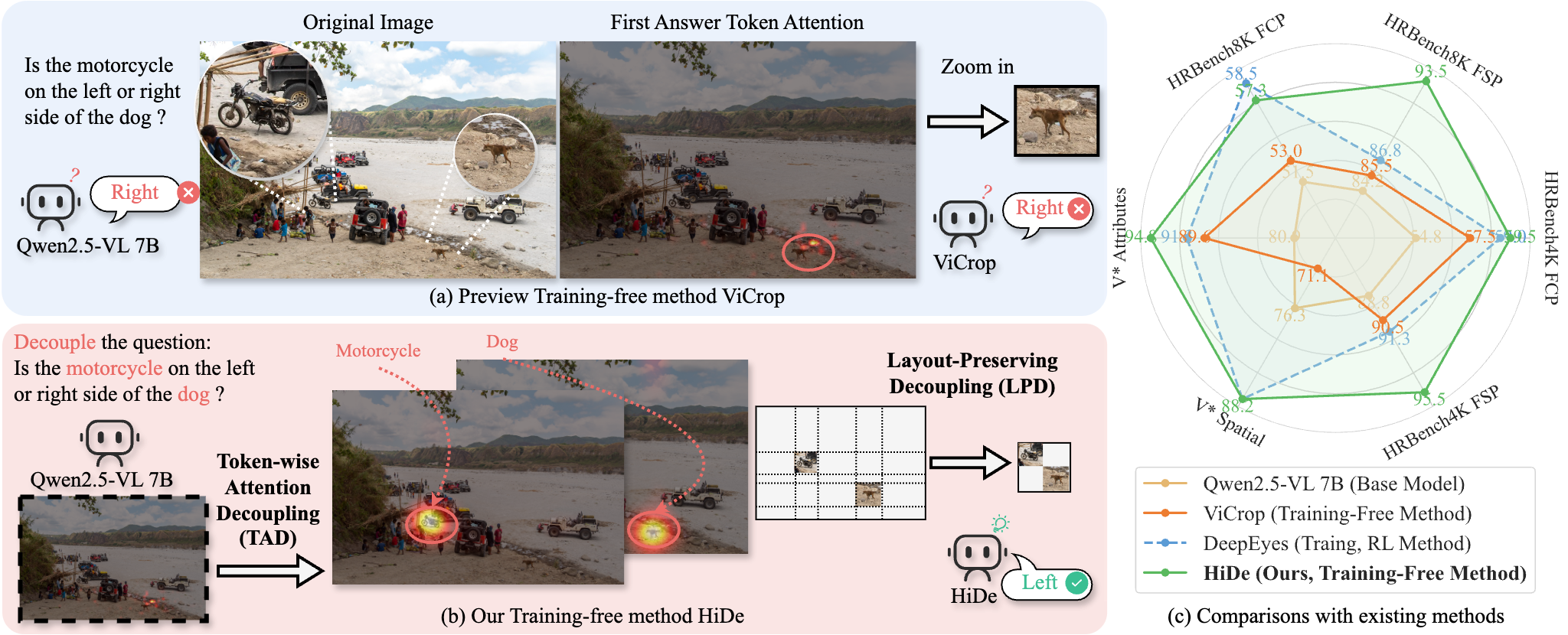
Figure 1: Hierarchical decoupling analysis of the zoom-in operation. We systematically decompose the zoom-in strategy to identify the key factors that contribute to performance improvements.
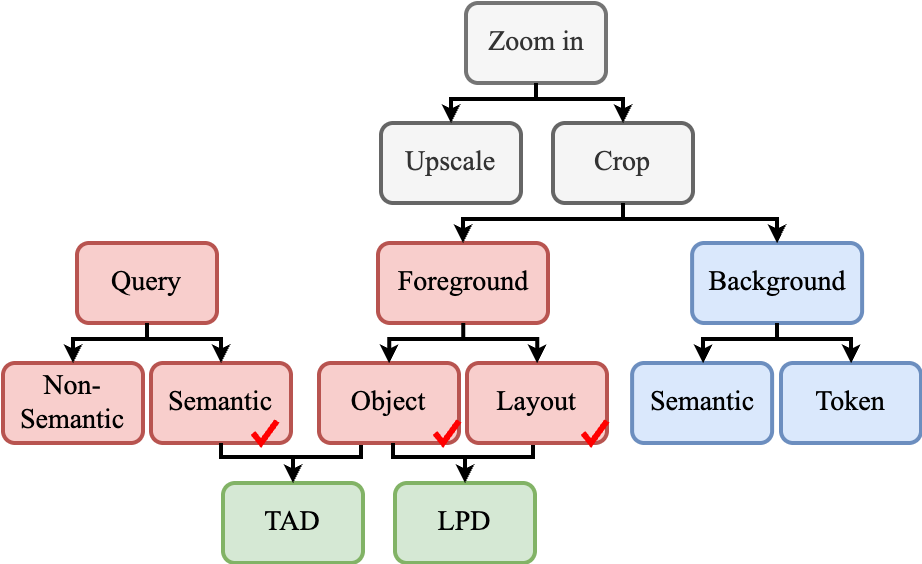
Figure 2: Our analysis framework: (i) Zoom-in upscale and crop, (ii) Crop foreground and background, (iii) Question text semantic and non-semantic tokens, (iv) Foreground object appearance and spatial layout.
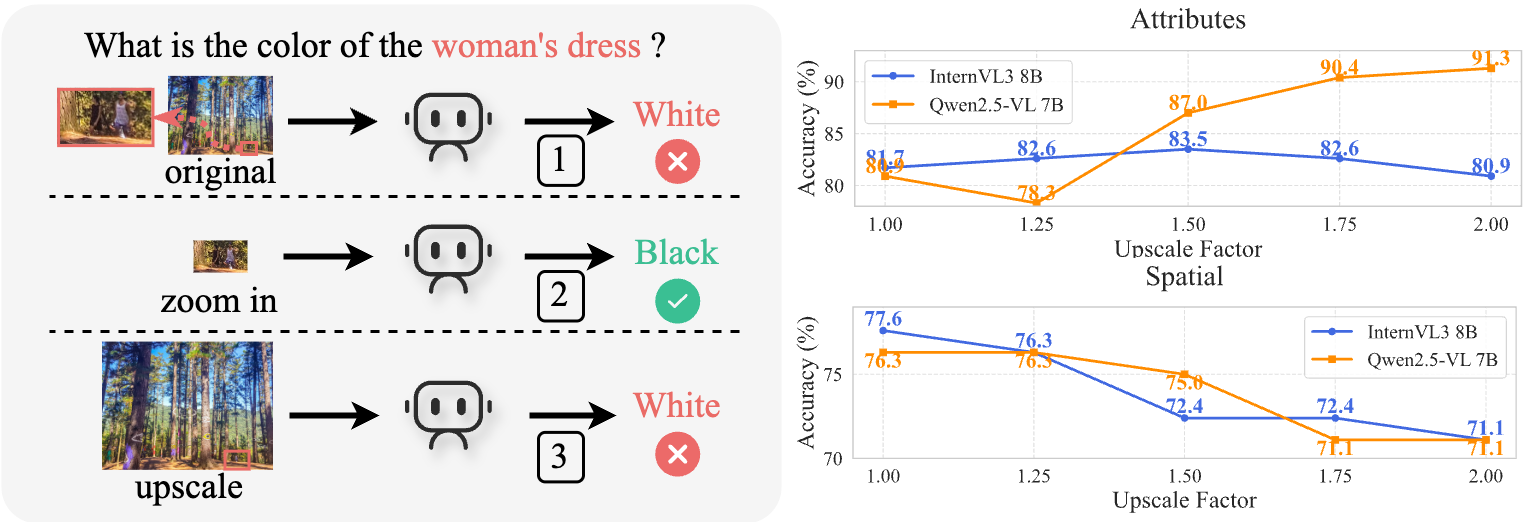
Figure 3: Simply enlarging the object does not deliver stable gains; on multi-object tasks, magnification can even hurt performance. Zoom-in works primarily because cropping removes irrelevant background.
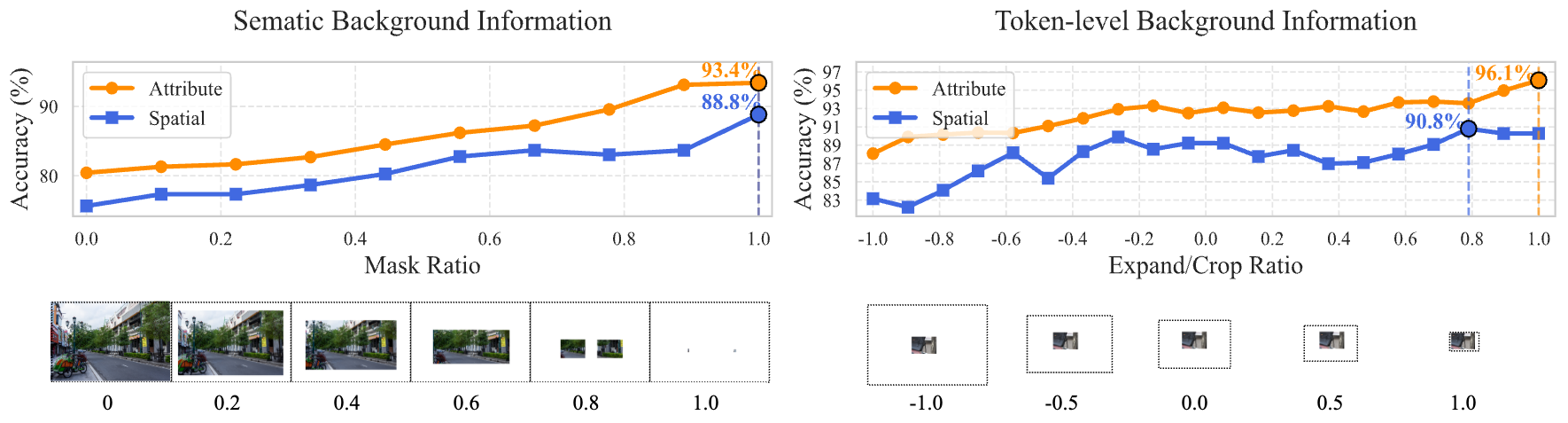
Figure 4: Performance increases monotonically with mask ratio on both single and multi-object tasks, demonstrating that complex background semantics significantly distract MLLMs.
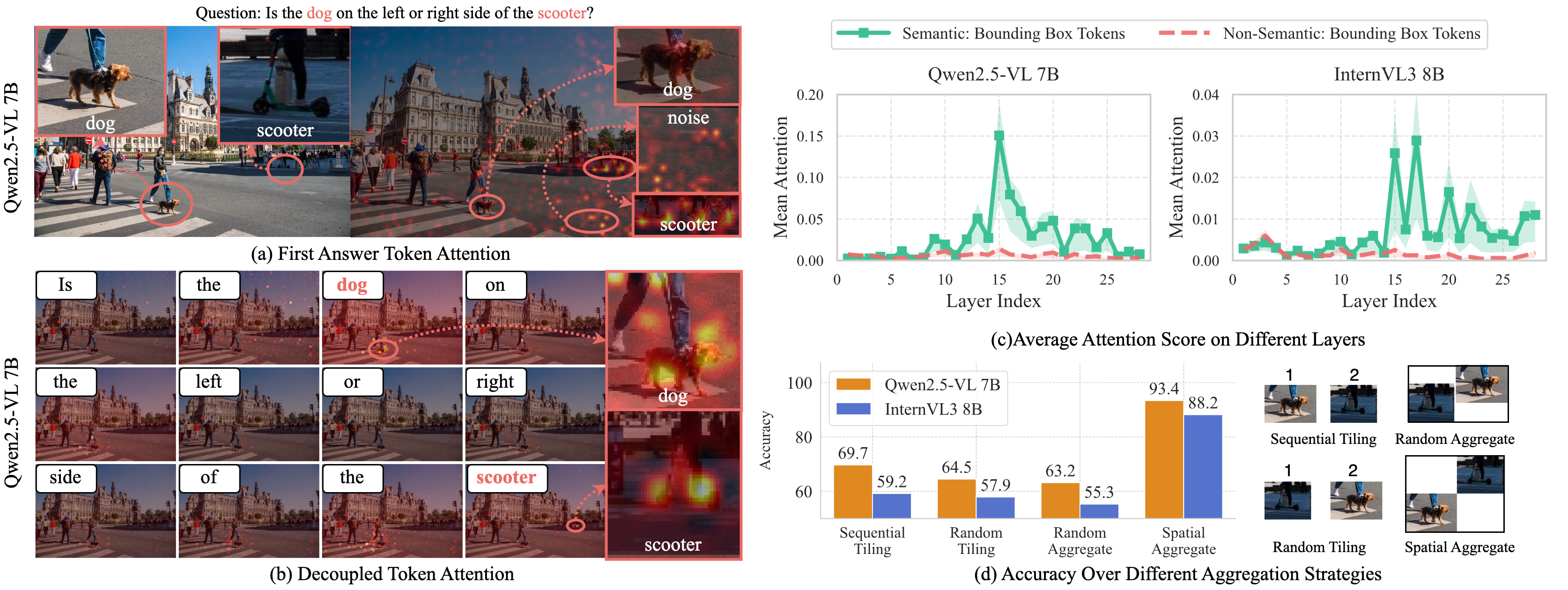
Figure 5: Semantic tokens exhibit substantially higher attention to GT regions than non-semantic tokens, confirming that token-level attention decoupling yields more accurate region proposals.